当推理负载从试验集群扩展到真实业务,「全部集中在超大规模数据中心」往往不再是默认最优解。本文从延迟、带宽、可用性与合规出发,梳理边缘节点、区域机房与中心集群的分层逻辑,说明混合拓扑下的任务切分、数据边界与运维治理要点,并与 AI 基础设施整体链条形成对照阅读。
在公共叙事里,AI 算力常与「超大规模数据中心 + 高端 GPU」绑定。对训练与部分集中式推理而言,这一定义大体成立。AI 基础设施,推理请求分布广、时延敏感、数据不能离域,且网络中断或峰值拥塞不可接受。此时,推理拓扑本身成为基础设施问题:算力不仅要有,还要出现在「正确的地理位置与正确的网络层级」上。
若将 AI 基础设施理解为自芯片向上延伸至服务与治理的连续链条,本文聚焦 拓扑与部署形态:如何在边缘、区域与中心之间分配计算与数据,使系统在延迟、成本、可用性与合规之间取得平衡。更上游的电力、封装与 HBM 等议题,更适合在供给侧专题中展开;企业侧多模型路由与 Agent 治理细节,则与生产运行体系专题相互补充。
为何需要讨论「分布式推理拓扑」
集中式推理的优势在于运维统一、弹性扩缩与资源复用率高。但当业务出现以下特征之一时,拓扑决策会显著影响体验与成本:
-
强时延约束:工业控制、实时交互、音视频链路、线下门店等对尾延迟敏感,回源路径过长会放大抖动。
-
数据主权与驻留:个人信息、金融交易、政务与医疗等场景常要求数据不出域、不出境或不出指定区域。
-
回源带宽与成本:海量终端持续上传原始数据到中心推理,骨干网与出口费用可能成为主成本项。
-
可用性与韧性:广域网故障、DNS 波动、跨区域拥塞时,纯中心架构更容易出现「全站不可用」的级联风险。
-
离线或弱网:矿山、船舶、部分制造现场等环境需要本地可运行能力,而不是强依赖实时在线。
这些问题无法仅靠「更强的中心模型」解决,因为它们的核心矛盾在 物理距离、网络路径与政策边界,而不是单次推理的算力峰值。
分层部署:边缘、区域与中心各自解决什么
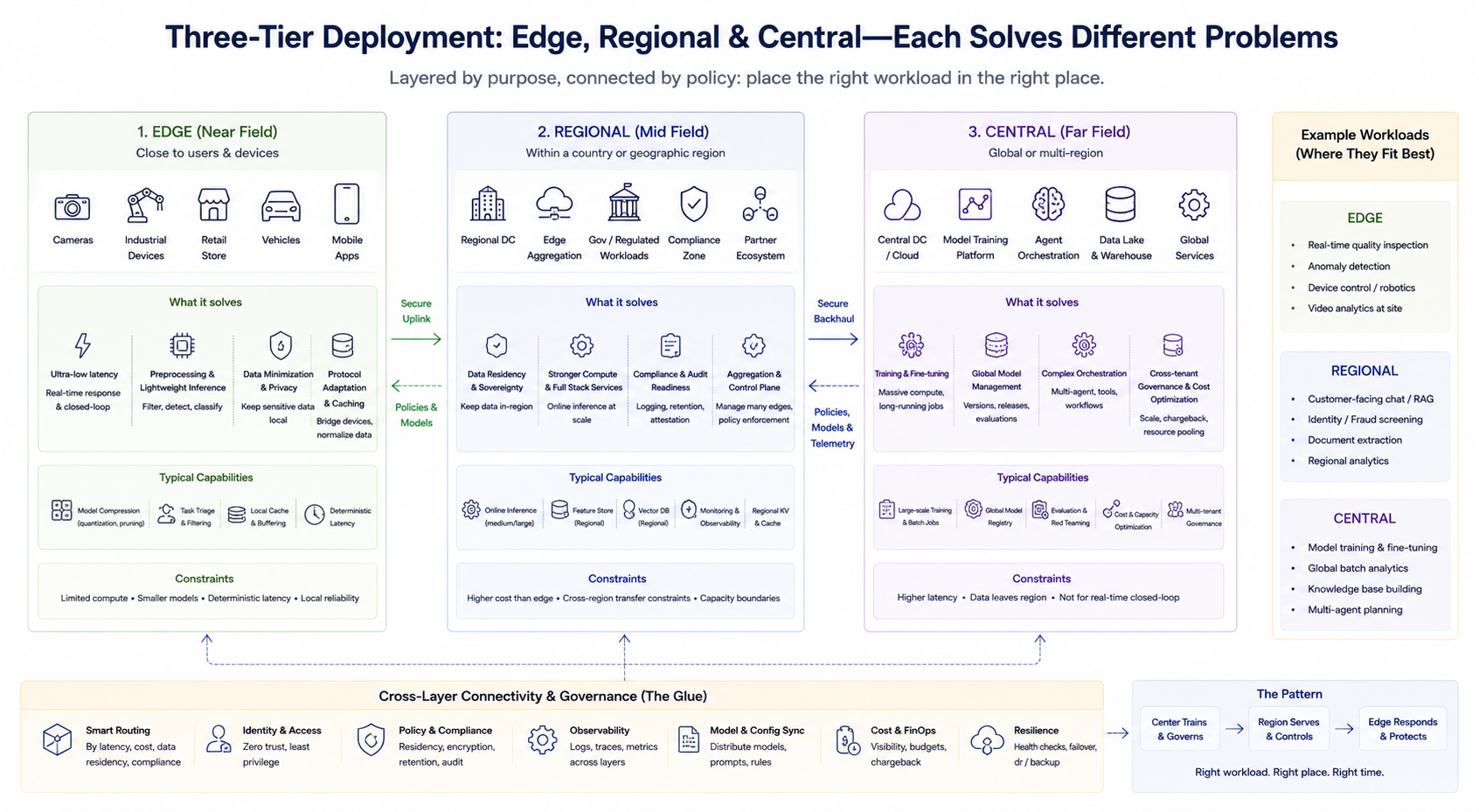
工程上常见做法不是二选一,而是分层组合。可以用一个简化框架理解各层职责(具体命名因厂商而异):
边缘层(近场)
靠近用户或设备,承担低延迟预处理、轻量推理、缓存与协议适配;适合实时闭环与敏感数据最小化上传。边缘算力通常受限,更强调模型压缩、任务裁剪与确定性时延。
区域层(中场)
在特定国家或地理区域内提供较强算力与较完整服务栈,用于满足数据驻留、合规审计与中等规模聚合推理;也常作为多边缘节点的汇聚与控制面。
中心层(远场)
承担训练、大规模批处理、全局模型管理、复杂 Agent 编排、跨租户统一治理与成本优化;适合对延迟不敏感但对算力与数据聚合要求高的工作负载。
三层之间不是固定等级关系,而是 按业务切分任务。同一企业可能同时存在:中心训练 + 区域在线推理 + 边缘实时检测,并通过路由策略把请求送到合适层级。
任务切分:哪些留在边缘,哪些回到中心
切分原则通常围绕 数据最小化、延迟预算、模型复杂度与更新频率 四条轴展开。
适合倾向边缘的任务(在满足算力前提下)
-
实时特征提取、目标检测、质量抽检等低延迟闭环
-
本地脱敏后的轻量推理(例如仅上传特征向量而非原始媒体)
-
弱网环境下的兜底推理与缓存命中策略
适合倾向中心或区域的任务
-
需要大上下文、强模型、复杂工具链或多系统编排的 Agent 流程
-
需要跨部门数据聚合的分析型推理
-
需要集中审计与统一密钥管理的敏感调用
切分错误的典型表现包括:把大模型长上下文强行塞进边缘导致 OOM;或把必须低延迟的闭环完全回源导致产线节拍失控。拓扑设计的目标不是「边缘越多越好」,而是 在约束条件下把正确的工作放在正确的位置。
数据主权与合规:拓扑倒推架构
数据主权要求会直接改变推理部署形态:模型可以下载到本地,但 日志、缓存、向量索引与调用轨迹 仍可能构成合规风险。实践中需要同时回答:
-
哪些数据必须留在边缘或区域内存储与计算
-
哪些元数据可以出境或上云,是否需要匿名化与留存周期
-
跨区域是否允许使用不同模型版本与不同供应商(避免「合规漂移」)
-
审计取证时能否还原「在某地、某时、基于何种数据片段」产生输出
这些问题的答案往往比「模型是否开源」更决定系统能否上线。换言之,合规不是边缘推理的附加项,而是拓扑设计的输入条件。
网络、电力与运维:分布式带来的真实成本
分布式推理的收益伴随系统性成本,需要在规划阶段显式评估:
-
网络:边缘与区域节点增加后,证书管理、专线 / SD‑WAN、DNS 与流量调度复杂度上升;多路径下尾延迟更难治理。
-
电力与机房:边缘站点分散,单位算力的能源效率与散热条件可能弱于大型数据中心;区域机房则介于两者之间。上游电力与机柜交付节奏仍会约束扩张速度,只是约束点从「单一园区」变为「多点并行」。
-
运维与版本一致性:模型、提示词、路由策略与索引在多点发布时,容易出现版本漂移;需要统一的发布管道、回滚策略与健康检查,否则排障成本会快速吞噬边缘带来的延迟收益。
-
安全面扩大:更多节点意味着更多证书、更多入口、更多本地存储介质;边缘环境物理安全与补丁节奏往往弱于中心机房,需要针对性的最小权限与远程管控策略。
因此,分布式拓扑不是「把算力推远」这么简单,而是 把一部分运维与治理复杂度外推到更接近业务现场的位置;若组织能力与平台工具未同步,拓扑优势难以兑现。
与中心推理的关系:混合架构如何落地
多数成熟方案采用 混合架构:中心负责训练、全局策略与重任务;区域负责合规区域内的在线服务;边缘负责低延迟与本地韧性。落地时常见工程模式包括:
-
分层缓存与结果复用:边缘命中高频请求,未命中再回源;需定义缓存键、TTL 与敏感数据策略。
-
模型拆分与小模型前置:边缘运行检测或分类小模型,中心运行大模型融合与解释生成(按场景评估)。
-
异步回传与聚合:边缘先做实时决策,再将脱敏样本或指标异步回传用于模型迭代与监控。
-
统一控制面:路由、配额、观测与密钥管理尽量集中,执行面分散,以降低「每个边缘一套孤岛」的风险。
混合架构的关键成功因素,通常是 控制面统一 + 执行面分层,而不是简单增加节点数量。
结语
边缘与分布式推理讨论的本质,不是「去中心化口号」,而是 在延迟、带宽、合规与运维成本之间做工程取舍。当业务从 demo 走向规模化,拓扑选择会反过来塑造模型形态、网络架构与组织流程;忽视这一层,容易出现中心算力很强、现场体验仍不稳定的错位。
分享
目录


相关文章

GateClaw 与 AI Skills:Web3 AI Agent 的能力体系解析

解读 Vana 的野心:实现数据货币化,构建由用户主导的 AI 开发生态

一文盘点 Top 10 AI Agents

GateClaw 的核心功能:Web3 AI Agent 工作站能力解析

Sentient AGI:社区构建的开放 AGI
